3.1 物理内存的组织结构
体系结构: NUMA 与 SMP
- SMP (对称多处理器): 一致内存访问 (UMA),所有处理器访问系统内存的时间是相同的 。
- NUMA (非一致内存访问): 内存被划分为多个内存节点,每个处理器有本地内存节点,访问本地节点速度快,访问远程节点相对较慢 [1]。
内存模型: 平坦、不连续与稀疏
- 平坦内存 (Flat Memory): 物理地址空间连续无空洞。若有空洞也会为其分配
page结构体,造成浪费 。 - 不连续内存 (Discontiguous Memory): 物理地址空间存在空洞,专门优化以不为空洞分配
page结构体 。 - 稀疏内存 (Sparse Memory): 物理地址空间不仅有空洞,还支持内存热插拔(动态插入/拔出物理内存) 。
三级管理结构: Node、Zone 与 Page
- 节点 (Node): 使用
pglist_data结构描述,包含该节点下的内存区域数组和备用列表等。 - 区域 (Zone): 节点被划分为不同区域,常见的有:
- ZONE_DMA: 用于较老的只能访问16MB以下物理内存的设备直接内存访问。
- ZONE_NORMAL: 普通区域,物理页可以被线性/直接映射到内核的虚拟地址空间。
- ZONE_HIGHMEM: 高端内存,32位系统中由于内核虚拟空间有限,无法将所有物理内存直接映射,超出部分即为高端内存 。
- ZONE_MOVABLE: 虚拟的可移动伪区域,纯粹是为了防止内存碎片而设立的机制 。
- 物理页 (Page): 系统物理内存的最小管理单位,通过
struct page描述页帧状态、引用计数、映射关系等 。
3.2 物理内存分配:伙伴系统 (Buddy System)
核心算法: 阶 (Order) 的拆分与合并
- 分配与合并: 伙伴系统按“阶”管理连续的物理页块,每个 n 阶页块包含 2^n 个连续页。若请求 n 阶页块但无空闲,系统会将 n+1 阶的页块“拆分”成两个互为“伙伴”的 n 阶页块,一个分配,一个留用。释放时,若两个伙伴均空闲,则自动“合并”成一个 n+1 阶的更大页块,以此消除外部碎片。
分配优化与防御碎片: PCP 与 可移动性分组
- 每处理器页集合 (PCP): 针对单页(0阶)分配的性能优化。系统为每个CPU和内存区域维护了一个包含缓存热页/冷页的单页链表,申请和释放单页时执行批量操作,大幅减少多核CPU间的锁竞争。
- 根据可移动性分组: 为防止长期运行产生的内存碎片,内核将物理页分为不可移动页(内核分配)、可回收页(如文件缓存)、可移动页(用户进程映射页)。通过将不可移动的页集中在一起,防止它们像“钉子”一样散布在可移动页中间阻碍大块内存的合并 。
水位管理: Watermark (min, low, high)
- 每个Zone维护三条水位线以控制可用内存:当空闲页少于
low水线时,内核会唤醒kswapd守护线程异步回收内存;若继续跌破min水线,则触发直接回收 (Direct Reclaim) ,强行阻塞当前进程进行内存回收。
3.3 小块内存分配:Slab/Slub/Slob 块分配器
核心理念: 面向对象缓存
为了解决伙伴系统只能按整页分配而导致的小对象内存浪费,Linux引入了块分配器。它预先向伙伴系统申请大块页帧(Slab),然后切分为指定大小的小块对象(如 task_struct),对象释放后不立即还给伙伴系统,而是留在缓存中,提高后续分配速度及处理器高速缓存命中率 。
三大分配器演进:
- SLAB: 经典的分配器,采用 Slab着色 (Coloring) 技术(让不同slab的首个对象在页内的偏移量不同,从而映射到CPU不同的硬件高速缓存行,避免缓存行过度竞争)。但其复杂的队列管理会导致较大的数据结构内存开销 [17-19]。
- SLUB: 现今内核的默认分配器。为了解决SLAB在大型计算机上的扩展性问题,SLUB抛弃了复杂的描述符和着色机制,将slab的管理信息精简并巧妙地存放在原有的
struct page中,极大降低了内存开销 。 - SLOB: 为内存受限的微型嵌入式设备设计的极简分配器,仅基于简单的块链表和最先适配算法实现。
3.4 虚拟地址空间与内存映射
虚拟内存区域: VMA (vm_area_struct)
进程的虚拟地址空间由多个虚拟内存区域(VMA)组成,用来表示代码段、数据段、堆、内存映射区等。VMA包含了虚拟地址范围 (vm_start, vm_end)、访问权限 (vm_page_prot)、操作集合 (vm_ops,含触发缺页中断的 fault 方法) 等信息 。
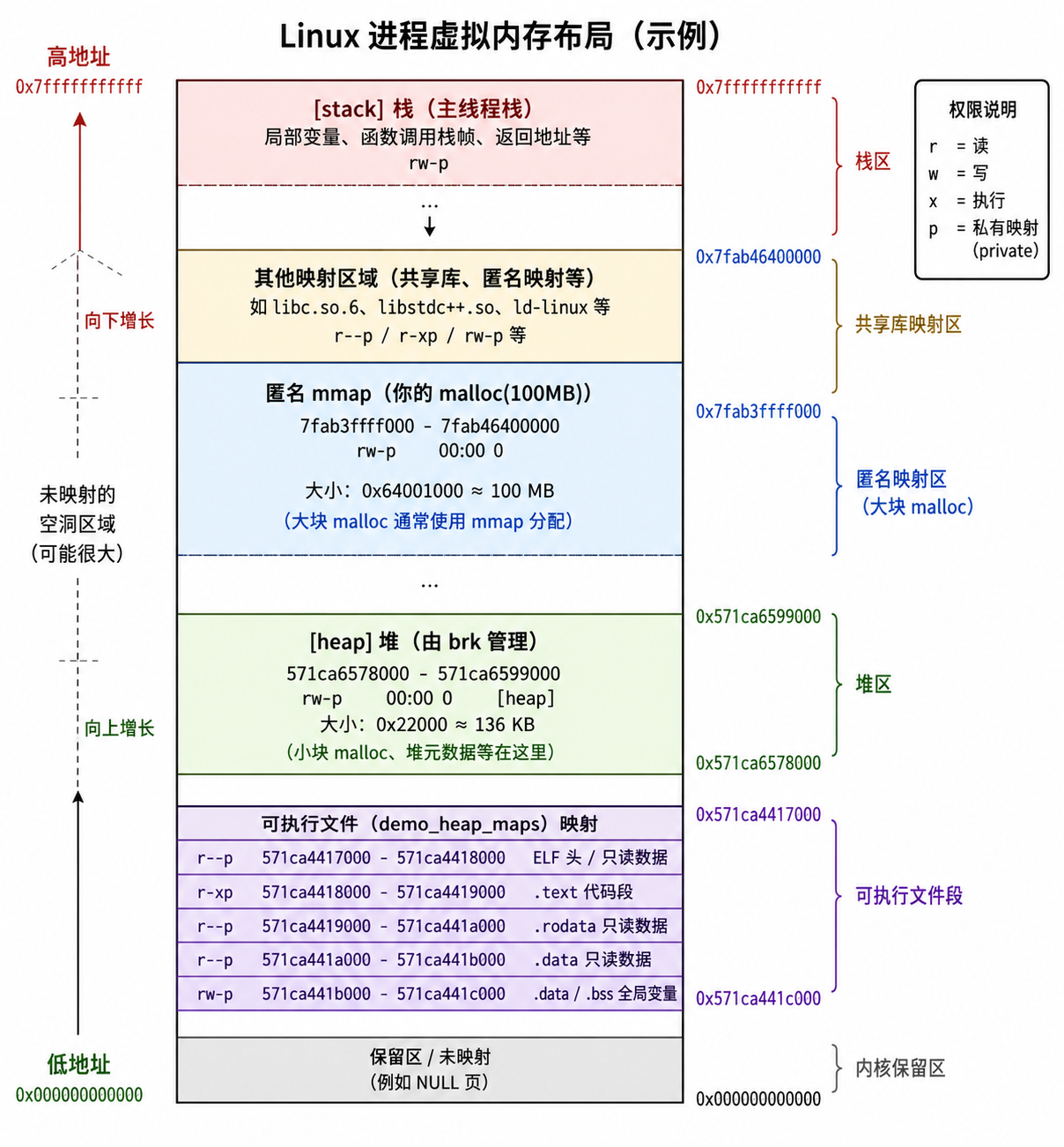
过量提交策略: Overcommit
Linux 允许所有进程申请的虚拟内存总和超过物理内存容量,称为虚拟内存过量提交 。内核支持三种策略:
- GUESS: 默认策略,估算可用内存(空闲页+可回收的文件页/缓存等),若充足则允许映射 。
- ALWAYS: 总是允许分配虚拟内存,假定进程申请后并不会真的全部写入 。
- NEVER: 严格限制,申请总量不能超过 (物理内存 - 巨型页) * 比例 + 交换区空闲页数 。
非连续页分配: vmalloc
当内核需要分配超大内存块但物理内存碎片化严重无法满足时,会使用 vmalloc 分配物理上不连续、但虚拟地址连续的内存,通过修改内核页表将分散的物理页拼接到 vmalloc 虚拟地址空间中 。
3.5 内存回收与内存碎片处理
反向映射 (Reverse Mapping, RMAP):
在回收由于缺页中断被映射的物理页时,内核需要修改对应进程的页表解除映射。反向映射机制通过 anon_vma (管理匿名页) 和 address_space.i_mmap 优先树 (管理文件页) 使得内核能通过物理页帧反向找到所有映射它的 VMA 和进程 。
页回收策略与 LRU 链表:
内核使用近期最少使用 (LRU) 算法回收内存。分为匿名页 (无后备文件,需写出到 Swap 交换区) 和 文件页 (有后备设备,脏页写回磁盘,干净页直接丢弃) 。
- LRU向量包含5条链表:不活动匿名页、活动匿名页、不活动文件页、活动文件页、不可回收页。回收时优先从“不活动”链表的尾部剔除页面 。
内存碎片整理: Compaction
当系统长期运行导致碎片化严重,无法分配大块连续物理内存时,触发内存紧缩。其原理是:迁移扫描器从内存区底部向上寻找“可移动”的已分配页,空闲扫描器从顶部向下寻找空闲页,二者相遇时,将底部的可移动页数据复制并搬移到顶部的空闲页中,从而在底部腾出大块连续的空闲物理页 。
最后防线: OOM Killer (内存耗尽杀手)
当系统内存严重不足,且多次进行直接页回收和碎片整理都无法获得可用内存时,内核将触发 OOM Killer。它会计算每个进程的“坏蛋分数” (Badness Score,主要基于进程及其占用的常驻内存、换出页数等考量),挑选得分最高的进程将其强制杀死 (kill) 从而释放内存保全系统 。
4.1 内存寻址的核心概念
地址转换机制: 逻辑地址 \rightarrow 线性地址 \rightarrow 物理地址
- 逻辑地址 (Logical Address): 包含在机器语言指令中用来指定操作数或指令的地址。在 80x86 架构中,逻辑地址由一个 16 位的段选择符 (Segment Selector) 和一个 32 位的偏移量 (Offset) 组成 。
- 线性地址 (Linear Address): 也称虚拟地址,通常是一个 32 位或 64 位的无符号整数。硬件中的分段单元 (Segmentation Unit) 负责将逻辑地址转换为线性地址 。
- 物理地址 (Physical Address): 用于内存芯片级内存寻址,与从微处理器地址引脚发送到内存总线的电信号相对应。硬件中的分页单元 (Paging Unit) 负责将线性地址转换为物理地址 。
4.2 操作系统的分段机制 (Segmentation)
核心组件: 段选择符、段寄存器与段描述符
- 段寄存器: 处理器提供专门的寄存器存放段选择符,包括 cs (代码段)、ss (栈段)、ds (数据段) 等。其中
cs寄存器还包含一个两位的字段,用于指明 CPU 当前的特权级 (CPL,0代表最高优先级/内核态,3代表最低优先级/用户态) 。 - 段描述符 (Segment Descriptor): 描述了段的具体特征(如基地址 Base、长度 Limit、特权级 DPL 等),存放在全局描述符表 (GDT) 或局部描述符表 (LDT) 中 。
- 转换过程: 分段单元通过段选择符在 GDT/LDT 中找到段描述符,然后将其 Base 字段的值与逻辑地址的偏移量相加,从而得到线性地址 。
Linux 中的分段实现: 弱化分段
- Linux 非常有限地使用分段,而更偏向使用分页方式。所有进程共享相同的线性地址能使内存管理更简单,且便于将系统移植到支持分页的 RISC 架构处理器上 。
- 四大核心段: Linux 运行在用户态和内核态下的所有进程,统一使用相同的段来进行指令和数据寻址。它定义了四个主要段:用户代码段、用户数据段、内核代码段和内核数据段。这四个段的基地址全部被强制设为
0x00000000,长度限制为0xFFFFFFFF。 - 地址等价: 由于在 Linux 中所有段的基地址都为 0,因此逻辑地址的偏移量值与对应的线性地址值是完全一致的,这在逻辑上完全绕过了硬件分段机制的复杂性 。
4.3 操作系统的分页机制 (Paging)
核心概念: 页 (Page) 与 页框 (Page Frame)
- 分页单元将线性地址映射到物理地址。它把物理 RAM 划分成固定长度的页框(通常为 4KB),并把线性地址空间划分成同样固定长度的页 。
- 多级分页机制: 为了避免每个进程的页表占用过大的物理内存,现代操作系统普遍采用多级页表。例如,32 位的 80x86 默认使用两级分页(页目录和页表);若开启物理地址扩展 (PAE),则引入 3 级分页以支持高达 64GB 的内存寻址 。现代 64 位系统一般支持 3 到 4 级分页转换表 。
- 页表项的重要标志位:
- Present: 指明该页当前是否在主存中。若不在主存中,处理器会触发一个缺页异常 (Page Fault),交由内核处理 。
- Accessed / Dirty: Accessed 标志在页被寻址时由硬件设置;Dirty 标志在对页进行写操作时设置,用于页面置换(回收)算法 。
- Read/Write & User/Supervisor: 用于实施页级别的存取权限和特权级保护控制 。
Linux 的分页模型: 统一的抽象框架
- 为了兼容不同 CPU 架构中差异巨大的硬件分页机制,Linux 采用了一种通用的多级分页模型 [13]。
- 内核采用了四级分页模型:页全局目录 (PGD)、页上层目录 (PUD)、页中间目录 (PMD) 和 直接页表 (PTE) [13]。而在较新版本中(如 Linux 4.11 版本之后),为了支持更大的地址空间,进一步扩展为了五级分页模型(新增了页四级目录 P4D)。
- 虚拟地址分解: 虚拟地址被按位划分为多个部分(如 PGD索引、P4D索引、PUD索引、PMD索引、PTE索引以及最后的页内偏移 Offset),通过层层索引定位物理页帧 。
- 自动适配硬件: 对于仅支持两级分页的底层硬件(如传统的 32 位系统),Linux 会在代码中模拟不需要的目录(如 PUD 和 PMD),将这些中间目录“折叠”或取消,使得通用的多级页表代码能完美适配底层硬件,而无需更改核心逻辑 。
4.4 页表缓存 (TLB)
TLB (Translation Lookaside Buffer): 地址转换的硬件加速
- 处理器的内存管理单元 (MMU) 在每次将虚拟地址转换成物理地址时,如果都去查询内存中的多级页表,会产生巨大的延迟。处理器内部引入了 TLB(转换后备缓冲区,即页表缓存)用于加速 。
- TLB 专门用来缓存最近使用过的页表映射项 。当进行进程上下文切换且修改了页目录基址寄存器时,硬件或操作系统需要使 TLB 中的相关旧数据失效(例如内核提供的
flush_tlb_all、flush_tlb_mm等函数机制)。 - 惰性 TLB (Lazy TLB) 优化: 为了避免进程切换时无谓地刷新 TLB 导致性能衰退,内核线程在运行时因为没有用户虚拟地址空间,会直接“借用”上一个用户进程的虚拟地址空间(
active_mm),从而避免了刷出 TLB 缓存项 。

