第四章:从一条记录说起-InnoDB记录结构 学习笔记
一、 磁盘与内存的交互基础
- 基本单位:页(Page)
InnoDB 引擎负责将表数据真正存储到磁盘上。因为磁盘 I/O 的速度远低于内存,如果按条读取数据会导致极低的性能。因此,InnoDB 将数据划分为若干个“页”,以页作为磁盘和内存之间交互的基本单位。 - 页的大小:通常情况下,一个页的大小默认是 16KB。这意味着,每次至少从磁盘读取 16KB 的数据到内存,或者将 16KB 的数据从内存刷新到磁盘。
二、 InnoDB 行格式 (Row Format) 简介
数据是以一条条“记录(行)”的形式插入到表中的。这些记录在磁盘上的物理存放方式,被称为行格式或记录格式。
- InnoDB 至今设计了 4 种类型的行格式:Compact、Redundant、Dynamic 和 Compressed。
- 指定方式:可以在创建表或修改表时显式指定行格式,语法如
CREATE TABLE 表名 (列的信息) ROW_FORMAT=COMPACT;。
三、 COMPACT 行格式详解
COMPACT 是非常经典且基础的行格式,它将一条记录分为两大部分:记录的额外信息 和 记录的真实数据。
1. 记录的额外信息
用于描述这条记录本身的元数据,包含三个部分:
- 变长字段长度列表:针对 VARCHAR、TEXT 等变长类型列,这里会逆序记录它们实际存储数据占用的字节长度。
- NULL值列表:把所有允许为 NULL 的列统一管理,如果某列实际值为 NULL,对应位标记为 1,这样可以节省物理存储空间。
- 记录头信息(Record Header):固定占用 5 个字节,包含诸多极其重要的标志位,核心的有:
delete_mask:标记该记录是否被删除(软删除机制)。record_type:记录类型(0为普通记录,1为B+树非叶节点记录,2为最小记录,3为最大记录)。next_record:下一条记录的相对偏移量。页内的所有记录正是通过这个指针串联成一个按主键递增的单向链表。n_owned和heap_no:用于记录所属的页目录分组以及在堆中的位置信息。
2. 记录的真实数据
除了我们自己在建表时定义的列以外,InnoDB 还会默认为每一条记录强行添加几个隐藏列:
row_id(6字节):行标识符。InnoDB 的主键生成策略是:优先使用用户自定义的主键 -> 没有则寻找一个不含 NULL 值的 Unique 键 -> 若都没有,才会自动添加这个row_id列作为隐藏主键。transaction_id(6字节):事务ID,记录是哪个事务最后修改了这条记录(必须存在)。roll_pointer(7字节):回滚指针,用于配合 undo 日志实现多版本并发控制(MVCC)(必须存在)。
3. VARCHAR 长度限制
规定指出,表中一行数据的所有列(不包括隐藏列和记录头信息)占用的总字节数不能超过 65535 字节。因此,VARCHAR(M) 中 M 的最大值取决于该字段使用的字符集(如 ascii 是单字节,gbk 最多 2 字节,utf8 最多 3 字节)。
四、 Dynamic 和 Compressed 行格式
这两种是较新版本 MySQL(如 5.7+)的默认行格式。它们与 COMPACT 的结构基本相同,主要区别在于处理行溢出(单条记录极大,一个 16KB 的页装不下)时的策略:
- Dynamic:当发生行溢出时,不在真实数据处存储溢出列的前 768 个字节,而是把所有的字节都转移到其他专门的溢出页面中,本页面只保留一个指向溢出页面的内存地址。
- Compressed:处理溢出的机制与 Dynamic 相同,但它会额外采用 zlib 压缩算法对页面进行压缩,以节省磁盘空间。
五、 数据页的内部存储结构
一个 16KB 的数据页内,包含了空间分配、目录管理、链表关联等复杂机制。
- User Records (用户记录):我们自己插入的记录都放在这里。初始始化时这个区域不存在,每插入一条记录,就从 Free Space (空闲空间) 中划出一块分配给 User Records。
- 记录的删除与复用:当我们删除一条记录时,它并不会被立刻从磁盘抹去,而是将其头信息的
delete_mask置为 1,并加入到一个垃圾链表中。之后插入的新记录可以直接覆盖并复用这些空间,避免了频繁的内存碎片整理带来的性能损耗。
六、 页目录 (Page Directory) 与二分法查询
既然页内记录是用单向链表连接的,如果每次查找某条记录都从头遍历,效率会极其低下。为了实现快速查找,InnoDB 引入了类似于书本目录的机制:Page Directory。
- 分组与槽 (Slot):InnoDB 会将页内的所有记录(包含自动生成的最小记录和最大记录)划分为若干个组。每个组中主键值最大的那条记录的地址偏移量会被提取出来,按顺序存放到 Page Directory 中。这些偏移量被称为槽 (Slot)。
- 快速查找过程:当我们要根据主键查找记录时:
- 通过二分法在 Page Directory 中快速定位到该主键值所在的“槽”。
- 根据槽找到该组的第一条记录,然后顺着单向链表向后精准遍历(因为每一组最多只有 8 条记录,此时遍历的代价微乎其微)。
七、 页的其他重要组成部分
除了存储记录和目录,数据页还包含头尾等元信息结构:
- Page Header (页面头部):记录当前数据页的状态信息,例如本页有多少条记录、页目录里有多少个槽、下一个可用空间的指针位置等。
- File Header (文件头部):记录页的通用信息,最重要的属性是它记录了上一页和下一页的页号指针。这使得所有的页不仅内部有链表,宏观上各个页之间也组成了一个宏大的双向链表。
- File Trailer (文件尾部):占用固定的 8 个字节,包含校验和 (Checksum) 与 LSN。它的作用是在数据从内存同步到磁盘时,校验页的完整性,防止断电等意外导致数据只写入一半而造成文件损坏。
本章核心总结:
记录不是零散地躺在硬盘里,而是被封装在带有格式规则的行格式中;一堆记录被放在 16KB 的数据页里;页内的记录按主键从小到大连成单向链表;为了加快在页内找记录的速度,InnoDB 提取了关键记录的偏移量做成了页目录 (Page Directory) 支持二分查找;最后,各个数据页之间又通过双向链表串联在了一起。理解这套精密的存储体系,是后续理解 B+ 树索引结构的前提。
完整实践:
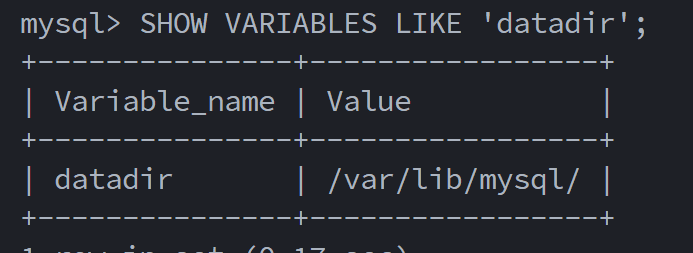
首先找到mysql存储数据的文件路径:
SHOW VARIABLES LIKE 'datadir';
一般都是:
root@VM-0-6-ubuntu:/var/lib/mysql# ls
auto.cnf binlog.000007 binlog.000012 binlog.000017 binlog.000022 binlog.000027 binlog.000032 ca.pem '#ib_16384_1.dblwr' '#innodb_temp' public_key.pem undo_002
binlog.000003 binlog.000008 binlog.000013 binlog.000018 binlog.000023 binlog.000028 binlog.000033 client-cert.pem ib_buffer_pool mysql server-cert.pem VM-0-6-ubuntu.pid
binlog.000004 binlog.000009 binlog.000014 binlog.000019 binlog.000024 binlog.000029 binlog.000034 client-key.pem ibdata1 mysql.ibd server-key.pem
binlog.000005 binlog.000010 binlog.000015 binlog.000020 binlog.000025 binlog.000030 binlog.index debian-5.7.flag ibtmp1 performance_schema sys
binlog.000006 binlog.000011 binlog.000016 binlog.000021 binlog.000026 binlog.000031 ca-key.pem '#ib_16384_0.dblwr' '#innodb_redo' private_key.pem undo_001
里面存了很多日志和数据,每个数据库就是一个文件目录,例如我创建的testDB,进入该目录:
root@VM-0-6-ubuntu:/var/lib/mysql/testDB# ll
total 120
drwxr-x--- 2 mysql mysql 4096 Apr 21 15:21 ./
drwx------ 8 mysql mysql 4096 Apr 21 15:20 ../
-rw-r----- 1 mysql mysql 114688 Apr 21 15:21 t1.ibd
t1是我创建的表,里面有三条数据,直接十六进制解析下:
root@VM-0-6-ubuntu:/var/lib/mysql/testDB# hexdump -C t1.ibd | head
00000000 3b 61 ae 73 00 00 00 00 00 01 38 ad 00 00 00 01 |;a.s......8.....|
00000010 00 00 00 00 01 28 d0 96 00 08 00 00 00 00 00 00 |.....(..........|
00000020 00 00 00 00 00 02 00 00 00 02 00 00 00 00 00 00 |................|
00000030 00 07 00 00 00 40 00 00 40 00 00 00 00 05 00 00 |.....@..@.......|
00000040 00 00 ff ff ff ff 00 00 ff ff ff ff 00 00 00 00 |................|
00000050 00 01 00 00 00 00 00 9e 00 00 00 00 00 9e 00 00 |................|
00000060 00 00 ff ff ff ff 00 00 ff ff ff ff 00 00 00 00 |................|
00000070 00 00 00 00 00 05 00 00 00 00 ff ff ff ff 00 00 |................|
00000080 ff ff ff ff 00 00 00 00 00 01 00 00 00 02 00 26 |...............&|
00000090 00 00 00 02 00 26 00 00 00 00 00 00 00 00 ff ff |.....&..........|

这里主要是FILE HEADER和PAGE HEADER信息,并没有涉及数据,并且因为是page 0, 所以都是系统配置,例如区、page0特有的信息等等,之后我们在利用innodb_space工具直接查看我们已经插入的数据信息,深入探究底层数据页的存储。
root@VM-0-6-ubuntu:/var/lib/mysql/testDB# innodb_space -f t1.ibd space-page-type-regions
start end count type
0 0 1 FSP_HDR
1 1 1 IBUF_BITMAP
2 2 1 INODE
3 3 1 SDI
4 4 1 INDEX
5 6 2 FREE (ALLOCATED)
page 0 → FSP_HDR(表空间管理)就是上面输出的十六进制数据
page 1 → IBUF_BITMAP(插入缓冲)
page 2 → INODE(段管理)
page 3 → SDI(统计/元数据)
page 4 → INDEX(数据页)
page 5-6 → FREE(已分配但未使用)
root@VM-0-6-ubuntu:/var/lib/mysql/testDB# dd if=t1.ibd bs=16384 skip=4 count=1 | hexdump -C
1+0 records in
1+0 records out
16384 bytes (16 kB, 16 KiB) copied, 3.8342e-05 s, 427 MB/s
00000000 01 6a b8 ac 00 00 00 04 ff ff ff ff ff ff ff ff |.j..............|
00000010 00 00 00 00 01 28 ea a3 45 bf 00 00 00 00 00 00 |.....(..E.......|
00000020 00 00 00 00 00 02 00 02 00 c3 80 05 00 00 00 00 |................|
00000030 00 b1 00 02 00 02 00 03 00 00 00 00 00 00 00 00 |................|
00000040 00 00 00 00 00 00 00 00 00 99 00 00 00 02 00 00 |................|
00000050 00 02 02 72 00 00 00 02 00 00 00 02 01 b2 01 00 |...r............|
00000060 02 00 1c 69 6e 66 69 6d 75 6d 00 04 00 0b 00 00 |...infimum......|
00000070 73 75 70 72 65 6d 75 6d 01 00 00 00 10 00 19 80 |supremum........|
00000080 00 00 01 00 00 00 00 09 5a 82 00 00 00 9c 01 10 |........Z.......|
00000090 61 01 00 00 00 18 00 19 80 00 00 02 00 00 00 00 |a...............|
000000a0 09 5a 82 00 00 00 9c 01 1d 62 01 00 00 00 20 ff |.Z.......b.... .|
000000b0 bf 80 00 00 03 00 00 00 00 09 5a 82 00 00 00 9c |..........Z.....|
000000c0 01 2a 63 00 00 00 00 00 00 00 00 00 00 00 00 00 |.*c.............|
000000d0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00003ff0 00 00 00 00 00 70 00 63 01 6a b8 ac 01 28 ea a3 |.....p.c.j...(..|
00004000
直接关注表示记录的数据,其中有两段明显的十六进制值,infimum,supremum;后面紧跟的就是实际记录;
跟本文最开始讲的compact行格式相对应,一一分析:
01 00 00 00 10 00 19 80 |supremum........|
00000080 00 00 01 00 00 00 00 09 5a 82 00 00 00 9c 01 10 |........Z.......|
- 01:变长字段长度列表。name 是 VARCHAR,值是 'a',长度为 1 字节,所以这里记录 01。(如果有多个变长字段,会逆序存放)。
- 00:NULL 值列表。id 是主键不为空,name 允许为 NULL。因为 'a' 不是 NULL,所以这位是 00。
- 00 00 10 00 19:5个字节的记录头信息,跟前文对应,重点说最后两个字节的数据:00 19 是指针(Next Record Offset),表示当前记录的真实数据到下一条记录真实数据的偏移量。当前记录数据在 0x7F,0x7F + 0x19 (十进制25) = 0x98,下一条记录 id=2 正好在 0x98 处
- 80 00 00 01:接下来就是真实数据;InnoDB 中,为了让有符号整数在 B+ 树比较时能够按二进制直接排序,会将符号位(最高位)反转。正数的最高位原本是 0,反转后变成 1,所以就变成了 80 00 00 01。
- 00 00 00 00 09 5a:6字节的隐藏列,表示事务ID
- 82 00 00 00 9c 01 10:7字节的隐藏列,表示回滚指针
- 特殊说明:因为这个表有主键,所以不会有row_id这个隐藏列
- 61:最后一个字节;实际列 name='a'。ASCII 码中的小写字母 'a' 就是十六进制的 0x61。
后面两个记录跟这个格式一样,唯一要注意的是:注意看第三行的记录头 (在 0x000000AD 处):
它的 Next Record Offset 是 ff bf。这是一个负数(补码表示为 -65)。
当前位置在 0xB1,往前退 65 个字节:0xB1 - 0x41 (65的十六进制) = 0x70。
而0x00000070正好是 supremum,形成了闭环,进一步说明了行记录之间的链表:
单向链表的闭环:Infimum -> 行1 -> 行2 -> 行3 -> Supremum。

