第十章:条条大路通罗马-单表访问方法 学习笔记
本章主要介绍了 MySQL 如何执行单表查询(FROM 子句后只有一个表),以及 MySQL 查询优化器所采用的各种查询执行方式——也就是所谓的“访问方法(Access Method)”。
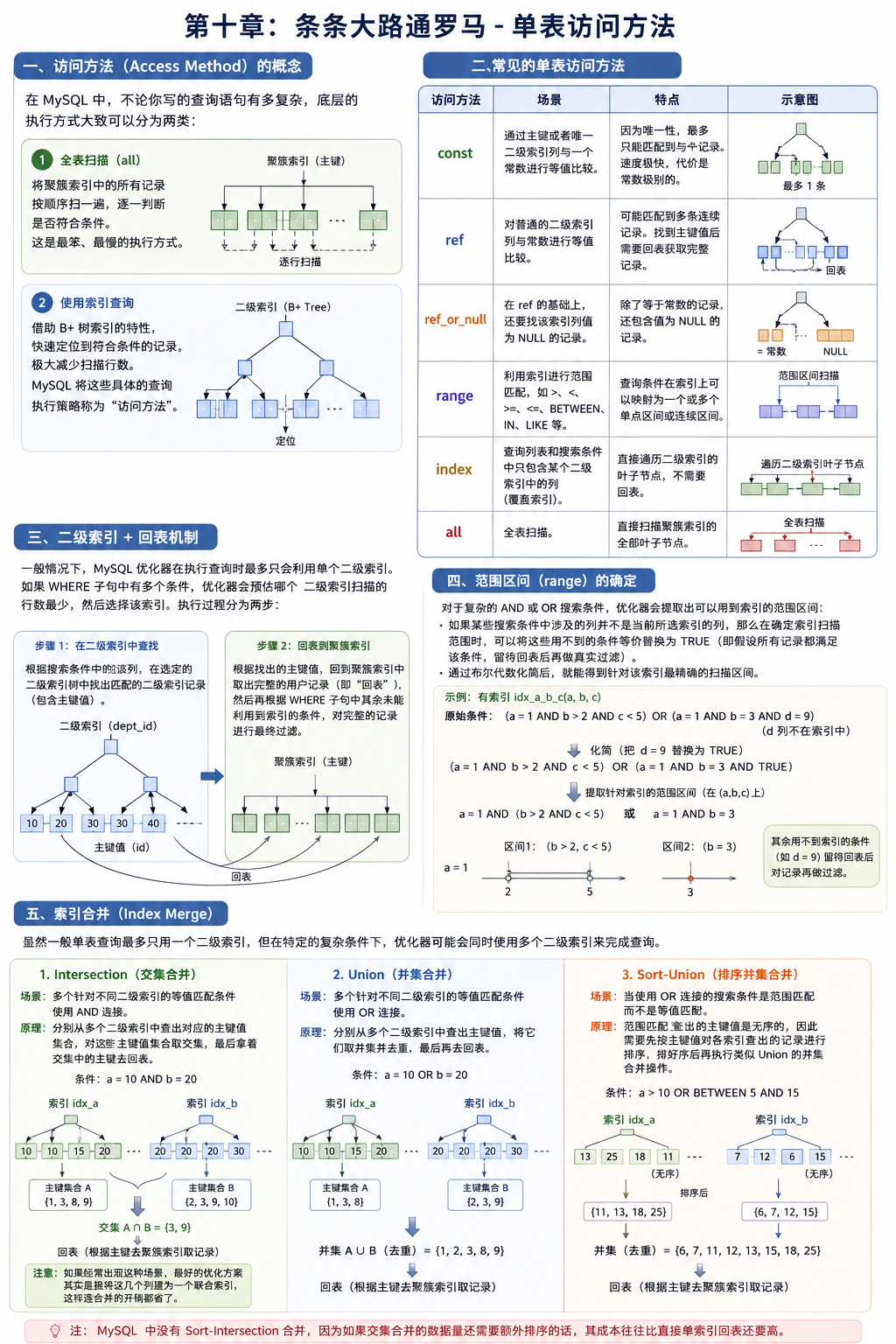
一、 访问方法(Access Method)的概念
在 MySQL 中,不论你写的查询语句有多复杂,底层的执行方式大致可以分为两类:
- 全表扫描:将聚簇索引中的所有记录按顺序扫一遍,逐一判断是否符合条件。这是最笨、最慢的执行方式。
- 使用索引查询:借助 B+ 树索引的特性,快速定位到符合条件的记录,极大减少扫描行数。
MySQL 将这些具体的查询执行策略称为“访问方法”。
二、 常见的单表访问方法
根据使用索引的类型和搜索条件的不同,单表访问方法主要有以下几种:
-
const
- 场景:通过主键或者唯一二级索引列与一个常数进行等值比较。
- 特点:因为主键或唯一二级索引的值是唯一的,所以最多只能匹配到一条记录。这种查询速度极快,代价是常数级别的,所以称为 const。
-
ref
- 场景:对普通的二级索引列与常数进行等值比较。
- 特点:普通二级索引不限制值的唯一性,所以可能会匹配到多条连续的记录。找到这些记录的主键值后,需要进行“回表”操作去聚簇索引中获取完整记录。在匹配记录数较少时效率依然很高。
-
ref_or_null
- 场景:在 ref 的基础上,不仅要找等于某个常数的记录,还要把该索引列值为 NULL 的记录也找出来。
-
range
- 场景:利用索引进行范围匹配。当搜索条件不仅是等值,还包含诸如
>,<,>=,<=,BETWEEN,IN,LIKE等操作符时。 - 特点:查询条件在索引上可以映射为一个或多个单点区间或连续区间。
- 场景:利用索引进行范围匹配。当搜索条件不仅是等值,还包含诸如
-
index
- 场景:当查询列表和搜索条件中只包含某个二级索引中的列时,虽然无法形成快速的范围扫描,但可以直接遍历该二级索引的叶子节点,而不需要回表。这其实就是利用了覆盖索引。
-
all
- 场景:全表扫描。
- 特点:直接扫描聚簇索引的全部叶子节点。
三、 二级索引 + 回表机制
一般情况下,MySQL 优化器在执行查询时最多只会利用单个二级索引。
如果 WHERE 子句中有多个条件,优化器会预估哪个二级索引扫描的行数最少,然后选择该索引。执行过程分为两步:
- 根据搜索条件中的该列,在选定的二级索引树中找出匹配的二级索引记录(包含主键值)。
- 根据找出的主键值,回到聚簇索引中取出完整的用户记录(即“回表”),然后再根据 WHERE 子句中其余未能利用到索引的条件,对完整的记录进行最终过滤。
四、 范围区间(range)的确定
对于复杂的 AND 或 OR 搜索条件,优化器会提取出可以用到索引的范围区间:
- 如果某些搜索条件中涉及的列并不是当前所选索引的列,那么在确定索引扫描范围时,可以将这些用不到的条件等价替换为 TRUE(即假设所有记录都满足该条件,留待回表后再做真实过滤)。
- 通过布尔代数化简后,就能得到针对该索引最精确的扫描区间。
五、 索引合并(Index Merge)
虽然一般单表查询最多只用一个二级索引,但在特定的复杂条件下,优化器可能会同时使用多个二级索引来完成查询,这被称为“索引合并”。主要有三种算法:
-
Intersection(交集合并)
- 场景:多个针对不同二级索引的等值匹配条件使用 AND 连接。
- 原理:分别从多个二级索引中查出对应的主键值集合,对这些主键值集合取交集,最后拿着交集中的主键去回表。
- 注意:如果经常出现这种场景,最好的优化方案其实是直接将这几个列建为一个联合索引,这样连合并的开销都省了。
-
Union(并集合并)
- 场景:多个针对不同二级索引的等值匹配条件使用 OR 连接。
- 原理:分别从多个二级索引中查出主键值,将它们取并集并去重,最后再去回表。
-
Sort-Union(排序并集合并)
- 场景:当使用 OR 连接的搜索条件是范围匹配而不是等值匹配时。
- 原理:范围匹配查出的主键值是无序的,因此需要先按主键值对各索引查出的记录进行排序,排好序后再执行类似 Union 的并集合并操作。
- (注:MySQL 中没有 Sort-Intersection 合并,因为如果交集合并的数据量还需要额外排序的话,其成本往往比直接单索引回表还要高)。
第十一章:两个表的亲密接触-连接的原理 学习笔记
在日常开发中,单表查询往往无法满足复杂的业务需求,我们需要将多个表的数据组合起来,这就是“连接(Join)”。本章主要深入探讨了 MySQL 底层是如何执行连接操作的。
一、 连接的本质
- 笛卡尔积:连接的本质就是把各个表中的记录都取出来进行依次匹配。如果表 A 有 3 条记录,表 B 有 4 条记录,把它们连接起来,在不加任何限制条件的情况下,就会产生 3 × 4 = 12 条记录,这在数学上被称为“笛卡尔积”。
- 过滤条件:因为纯粹的笛卡尔积通常包含大量无意义的组合,所以在实际查询时我们一定会附加上过滤条件,把真正有关联的、符合业务逻辑的记录筛选出来。
二、 连接执行的步骤与驱动表概念
在 MySQL 中,两表连接的底层执行过程实际上是由主次之分的:
- 驱动表(Driver Table):MySQL 首先会单表查询的一个表。在连接查询中,驱动表只会被查询一次。
- 被驱动表(Driven Table):MySQL 拿着从驱动表中查出的每一条符合条件的记录,去另一个表中查找匹配的记录,这另一个表就是被驱动表。在连接查询中,被驱动表可能会被查询多次。
- 执行步骤简述:先选定一个驱动表,根据过滤条件查出结果集;然后遍历这个结果集,针对每一条记录,分别到被驱动表中去寻找匹配的记录并拼接。
三、 内连接与外连接
- 内连接(Inner Join):对于内连接来说,如果驱动表中的记录在被驱动表中找不到匹配的记录,那么该记录不会加入到最后的结果集中。
- 外连接(Outer Join):在很多业务场景下,即便被驱动表中没有匹配的记录,我们也希望驱动表中的记录能保留在结果集中(缺失的字段用 NULL 填充)。外连接又分为:
- 左外连接(Left Join):选取左侧的表为驱动表。
- 右外连接(Right Join):选取右侧的表为驱动表。
四、 核心考点:ON 与 WHERE 的本质区别
这是连接查询中最容易踩坑的地方,尤其是在外连接中:
- WHERE 子句:它的作用是全局过滤。不论是内连接还是外连接,只要是不符合 WHERE 条件的记录,统统会被从最终结果集中踢除。
- ON 子句:它是专门为外连接服务的。在寻找被驱动表的匹配记录时,如果不满足 ON 条件,驱动表的这条记录依然会保留在结果集中,只是被驱动表的那部分字段全被置为 NULL。
- 注:在内连接中,WHERE 和 ON 的作用是完全等价的,MySQL 优化器会把它们当成一回事处理。
五、 嵌套循环连接(Nested-Loop Join, NLJ)
这是 MySQL 处理连接查询最基础、最原始的算法。
- 原理:用伪代码理解就是一个嵌套的 for 循环。外层循环遍历驱动表的结果集,内层循环对被驱动表进行全表查询。
- 性能痛点:假设驱动表过滤后有 1000 条记录,那就意味着被驱动表要被全表扫描 1000 次!如果被驱动表数据量很大,这种操作产生的磁盘 I/O 代价是极其恐怖的。
六、 索引加速连接
为了解决嵌套循环连接的龟速问题,核心优化点在于:加快对被驱动表的查询速度。
- 由于我们在被驱动表中查找数据时,通常会指定匹配条件(也就是 ON 后面的等值比较条件),因此我们强烈建议在被驱动表的连接列上建立索引。
- 这样一来,针对被驱动表的多次查询,就从极其缓慢的“多次全表扫描”变成了极其快速的“多次 B+ 树索引等值查找”,性能会得到质的飞跃。
七、 基于块的嵌套循环连接(Block Nested-Loop Join, BNL)
如果我们因为各种原因,实在无法给被驱动表建立索引,或者连接条件不适用索引怎么办?为了避免极度低效的多次全表扫描,MySQL 提出了一个权宜之计:Join Buffer(连接缓冲区)。
- 原理:MySQL 在内存中申请了一块名叫 Join Buffer 的区域。它不再是每次从驱动表拿一条记录去查被驱动表,而是先把驱动表里的一批记录统统装进 Join Buffer 中。
- 批处理比对:然后,只对被驱动表进行一次全表扫描。在扫描被驱动表的每一条记录时,直接在内存中让它和 Join Buffer 里的那一批驱动表记录进行比对。
- 优势:极大地减少了被驱动表的磁盘 I/O 扫描次数(虽然内存中的比对次数没变,但内存操作的速度远超磁盘)。
- 参数控制:可以通过系统变量
join_buffer_size来调节这块内存的大小。如果你的查询经常包含无法使用索引的复杂连接,适当调大这个值可以提升查询效率。
第十二章:谁最便宜就选谁-基于成本的优化 学习笔记
MySQL 内部有一个非常核心的组件叫做“查询优化器”。当执行一条 SQL 时,优化器会面临多种可能的执行方案(比如全表扫描、使用索引A、使用索引B等)。本章详细讲解了优化器是如何通过计算“成本”来决定最终使用哪种方案的。
一、 什么是执行成本
MySQL 在执行查询之前,会预估执行方案的代价,这个代价(成本)主要由两部分组成:
- I/O 成本:将数据页从磁盘加载到内存中消耗的时间。在默认情况下,MySQL 规定读取一个页面的 I/O 成本常数是 1.0。
- CPU 成本:读取记录以及对记录进行搜索条件比对、排序等操作消耗的时间。默认情况下,MySQL 规定读取并检测一条记录的 CPU 成本常数是 0.2。
- 总成本 = I/O 成本 + CPU 成本。
二、 单表查询的成本优化步骤
当针对单表进行查询时,优化器会严格按照以下四个步骤来选择最优的访问方法:
第一步:根据搜索条件,找出所有可能使用的索引
- 只要搜索条件中涉及了某个二级索引列,并且符合最左前缀等原则,该索引就会被列为“候选索引”。
第二步:计算全表扫描的代价
- 优化器会查看该表的统计信息(聚簇索引占用的页面数、表中的总记录数)。
- 代价 = (聚簇索引页面数 × 1.0) + (总记录数 × 0.2)。这是一个基准值。
第三步:分别计算使用各个候选索引的代价(核心)
使用二级索引执行查询的成本,取决于两个核心维度:范围区间的数量和需要回表的记录数。
- 范围区间 I/O 成本:优化器粗暴地认为,每扫描一个范围区间,就相当于读取一个页面的 I/O 成本。
- 记录的 CPU 成本与回表成本:优化器需要预估在这个范围区间内到底有多少条记录。
- Index Dive 技术:为了精准预估区间内的记录数,优化器会直接去二级索引的 B+ 树中,从根节点向下“潜水(Dive)”寻找区间的左右边界,以此来计算出该区间内的页面数和记录数。
- 预估出记录数后,由于是二级索引,每条记录还要回表。优化器认为,每次回表操作都相当于进行一次页面的随机 I/O(成本为 1.0)。
- 因此,使用二级索引的成本 = 区间数量的 I/O 成本 + 预估记录数的 CPU 成本 + 预估记录数的回表 I/O 成本。
第四步:对比各种执行方案的代价,找出成本最低的那一个
- 将全表扫描的成本与各个候选索引的成本进行对比,谁的数值最小,底层最后就真正使用哪种访问方法来执行查询。
三、 Index Dive 的局限与索引统计数据
- 当我们在查询条件中使用
IN (值1, 值2, ... , 值N)时,如果 N 的数量极其庞大(比如 IN 里面有几万个值),那么优化器就需要进行几万次 Index Dive,这个计算成本甚至会比直接查全表还要慢! eq_range_index_dive_limit变量:为了防止这种情况,MySQL 提供了一个系统变量(在 MySQL 5.7.3 后默认是 200)。如果 IN 语句中的参数个数超过了这个限制,优化器将放弃精准的 Index Dive,而是改用表中预先收集好的**“索引统计数据”**(如索引的基数 cardinality)来进行极其粗略的估算。这种估算速度极快,但不一定准确。
四、 连接查询的成本计算
连接查询的成本不仅要考虑单表,还要考虑表与表之间的嵌套循环。核心公式为:
- 连接查询总成本 = 驱动表的访问成本 + (驱动表的扇出值 × 被驱动表的访问成本)
- 什么是扇出(Fanout):驱动表经过所有的 WHERE 条件过滤后,最终能够输出给被驱动表进行匹配的记录条数。扇出值越小,对被驱动表的查询次数就越少,连接查询的总体成本就越低。
- 多表连接顺序优化:
- 对于内连接,任何表都可以作为驱动表。如果是 N 个表进行连接,就会有 N 的阶乘种不同的连接顺序。
- 优化器会尝试计算各种连接顺序的成本,并选出成本最低的一种作为最终的执行计划(这也就是为什么你写的 JOIN 顺序经常被底层偷偷改变的原因)。
- 为了防止表太多导致排列组合计算量爆炸,MySQL 提供了
optimizer_search_depth变量来限制评估不同连接顺序的深度,或者采用一些启发式规则直接剔除明显不合理的顺序。
五、 成本常数的微调
随着固态硬盘(SSD)的普及,将一次磁盘 I/O 成本固定设为 1.0 可能不再符合当下的硬件实际情况。
- MySQL 将这些内部使用的成本常数开放了出来,存储在
mysql系统数据库下的server_cost(包含 CPU 等操作成本)和engine_cost(包含特定存储引擎的 I/O 成本)两张表中。 - 高级 DBA 可以通过更新这两张表里的记录,然后执行
FLUSH OPTIMIZER_COSTS,来人工介入并微调优化器的评估倾向,使其更贴合当前的物理硬件性能。
第十三章:兵马未动,粮草先行-InnoDB统计数据是如何收集的 学习笔记
在第十二章中我们了解到,MySQL 优化器在评估执行成本时,极度依赖两项关键数据:聚簇索引占用的页面数和表中的大致记录数。本章详细解密了这些底层的“统计数据”究竟是从哪里来、如何存储以及何时更新的。
一、 统计数据的两种存储方式
InnoDB 提供了两种收集和存储统计数据的方式:
- 非永久性统计数据:将统计数据存放在内存中。这种方式在服务器重启后数据就会丢失,并且会在表发生较大变动或执行某些特定系统命令(如
SHOW TABLE STATUS)时重新计算。由于不够稳定且计算频繁,新版本中已不再推荐。 - 永久性统计数据:将统计数据持久化存放到磁盘中。服务器重启后数据依然存在,这是 MySQL 5.6.6 版本之后的默认工作方式。
可通过系统变量innodb_stats_persistent来控制开启哪种方式(默认开启永久性)。
二、 永久性统计数据的内部存储
开启永久性统计后,InnoDB 会将底层的统计信息偷偷存储在 mysql 系统数据库下的两个特殊表中:
innodb_table_stats(表级别统计信息):- 记录了表内数据的宏观情况。
- 最核心的字段包括:
n_rows(表中的预估记录条数)、clustered_index_size(聚簇索引占用的页面数)、sum_of_other_index_sizes(其他二级索引占用的总页面数)。
innodb_index_stats(索引级别统计信息):- 记录了每个索引的微观详细情况。
- 最核心的字段包括:该索引的 B+ 树层级高度、叶子节点数量,以及极其重要的 Cardinality(基数)。基数代表该索引列中不重复数据的预估数量,基数越大,说明列的区分度越高,优化器就越倾向于使用该索引。
三、 核心机制:随机采样统计
为了获取上述的统计数据,InnoDB 会不会把整张表从头到尾扫一遍?绝对不会,因为那样代价极其高昂。
- 采样机制(Sample):InnoDB 采用的是“以小见大”的随机采样法。它会从 B+ 树的叶子节点中随机抽取少量的几个数据页,统计这几个页里的记录数和区分度,然后用这个局部平均值去乘以总页数,从而“估算”出整张表的统计数据。
- 精准度与性能的博弈:采样的数据页数量由变量
innodb_stats_persistent_sample_pages控制(默认是 20 个页)。- 采样页越多,统计数据越精准,但收集成本越高,越容易影响正常的业务请求。
- 采样页越少,收集极快,但在数据分布不均匀的表中,极易产生巨大的统计误差。
四、 统计数据何时更新?
既然是采样估算,随着业务系统不断的 INSERT、UPDATE、DELETE,统计数据一定会逐渐失真。InnoDB 提供了自动和手动两种更新机制:
- 自动更新(后台异步):
- 受变量
innodb_stats_auto_recalc控制(默认开启)。 - 触发条件:当表中有超过 10% 的行数据发生修改时,InnoDB 就会在后台默默启动一个线程,重新进行一次随机采样,把新的统计数据更新到系统表中。
- 受变量
- 手动更新(强制同步):
- 适用场景:如果你在日常排查问题时,发现某个查询明明有极好的索引,优化器却偏偏选了全表扫描,这极大概率是因为统计数据严重失真(过期),且尚未达到自动更新的阈值。
- 解决命令:此时可以手动执行
ANALYZE TABLE 表名;命令。 - 注意警告:这个命令会强制 InnoDB 立即重新采样并更新统计数据。它是一个同步操作,如果是海量数据的大表,可能会造成短暂的阻塞,建议在业务低峰期执行。
五、 容易踩坑的 NULL 值处理
在统计某个列的基数(Cardinality)时,遇到值为 NULL 的记录该怎么算?
- MySQL 提供了
innodb_stats_method变量来决定对待 NULL 值的态度。你可以设置将所有 NULL 值视为同一个值,或者将每一个 NULL 都视为不同的值,亦或者在统计时直接忽略 NULL 值。 - 最佳实践:在设计数据库表时,尽量将列设置为
NOT NULL。如果列中存在大量的 NULL 值,不仅浪费存储空间,还会严重干扰 InnoDB 对索引基数的采样统计,进而诱导优化器生成极其糟糕的执行计划。
第十四章:基于规则的优化(内含子查询优化) 学习笔记
MySQL 优化器除了会根据成本来选择最优的执行计划外,在真正执行计算之前,还会根据一些内置的规则,对我们编写的 SQL 语句进行“重写”和“改造”。这个过程被称为基于规则的优化,其目的是让 SQL 语句变得更高效、更容易执行。
一、 简单的条件化简
我们在编写 WHERE 子句时,往往会写出一些逻辑上略显冗余的条件,优化器会自动帮我们进行精简:
- 移除不必要的括号:将原本多余的括号剥离,简化表达式结构。
- 常量传递(Constant Propagation):如果存在
a = 5 AND b > a,优化器会自动将其化简为a = 5 AND b > 5。 - 等值传递(Equality Propagation):如果有
a = b AND b = c AND c = 5,会被化简为a = 5 AND b = 5 AND c = 5。 - 移除没用的条件:比如
WHERE 1 = 1 AND a = 5会直接被剔除为WHERE a = 5;如果存在1 = 0这种绝对为假的条件,优化器甚至连表都不会去查,直接返回空结果。 - 表达式计算:
a = 5 + 1会被提前计算为a = 6。但要注意,如果对索引列使用函数或进行数学运算(如-a = -5或ABS(a) = 5),优化器是不会帮你进行化简的,这会导致该列无法使用索引。 - HAVING 子句与 WHERE 子句合并:如果查询语句中没有出现 GROUP BY 子句也没有聚集函数,优化器会直接把 HAVING 子句和 WHERE 子句合并起来处理。
二、 外连接消除(Outer Join Elimination)
在第十一章讲过,内连接中的表可以互换驱动表位置,优化器能自由比较谁做驱动表成本更低;而外连接(如左外连接)必须固定左表为驱动表,这极大限制了优化器的发挥空间。
- 空值拒绝条件(Reject-NULL):在左外连接中,如果被驱动表在匹配不到记录时本该用 NULL 填充,但我们在 WHERE 子句中恰好规定了被驱动表的某个列不能为 NULL(例如
WHERE 被驱动表.列 IS NOT NULL或者WHERE 被驱动表.列 = 5),这就意味着那些未能匹配的记录最终还是会被 WHERE 踢除。 - 优化策略:遇到上述情况,外连接和内连接的最终结果其实完全一样。此时,优化器会直接把外连接转换为内连接,从而打破驱动表的固定限制,重新评估并选择成本最低的表作为驱动表。
三、 子查询的分类
根据子查询返回的结果和与外层查询的关系,子查询可以分为:
- 按返回结果分类:
- 标量子查询:只返回一个单一的值(一行一列)。
- 行子查询:返回一条记录(一行多列)。
- 列子查询:返回一个列的数据(多行一列)。
- 表子查询:返回一个完整的表格数据(多行多列)。
- 按与外层查询的关系分类:
- 不相关子查询:子查询可以单独运行出结果,完全不依赖外层查询的条件。
- 相关子查询:子查询的执行依赖于外层查询的值(比如子查询里用了外层表的列作为条件)。
四、 核心重头戏:IN 子查询的优化策略
对于包含 IN 的列子查询(如 WHERE key1 IN (SELECT key3 FROM table2)),如果外层表和子查询表的数据量都很大,传统的嵌套循环执行会极其缓慢。MySQL 为此祭出了两把杀手锏:
1. 物化(Materialization)
- 原理:如果不相关子查询的结果集很大,MySQL 不会每次都去重新查。它会把子查询的结果集真正的“落地”存储到一个临时表中,并对其中的数据进行去重。
- 索引加速:如果临时表数据量不大,就放在内存里并建立哈希索引;如果数据量太大,就放到磁盘里并建立 B+ 树索引。之后外层查询再去判断 IN 的条件时,直接去这个带索引的临时表里极速查找即可。
2. 半连接(Semi-Join)
- 原理:将 IN 子查询直接改写成两表的连接查询。所谓半连接,是指对于外层表的一条记录,只要在子查询表中找到哪怕一条匹配的记录,外层表的这条记录就会被加入结果集,随后立即停止在子查询表中继续匹配当前外层记录(起到自动去重的效果)。
- 优势:一旦转换为半连接,子查询表和外层表就变成了平等的连接关系,优化器就可以自由选择谁来做驱动表,极大提升了执行效率。
- 半连接的具体执行策略:底层有 Table Pullout(表上拉)、Duplicate Weedout(重复值消除)、LooseScan(松散扫描)、FirstMatch(首次匹配)等多种算法,优化器会通过成本计算选择最合适的一个。
五、 ANY/ALL 子查询的转化
当我们在条件中使用 ANY 或 ALL 操作符搭配子查询时(例如 < ANY (SELECT ...)),优化器通常不会傻傻地去遍历比较,而是将其等价转换为聚集函数:
< ANY会被转换为< MAX(只要比子查询里的最大值小就行)。> ALL会被转换为> MAX(必须比子查询里的最大值还要大)。
这种简单的聚集替换,使得繁琐的子查询判断瞬间变成了常数级别的比较。
本章核心总结:
优化器是个非常聪明的管家,它不仅会做数学题算成本,还会帮你“改写代码”。它会自动精简我们写的啰嗦条件;把满足条件的外连接巧妙地转为内连接;对于最让人头疼的 IN 子查询,它更是提供了物化临时表和**半连接(Semi-Join)**等极其高端的改写技术,将原本指数级的时间复杂度硬生生降维打击到了可控的范围内。

